
{kind=link}
Welcome to this comprehensive guide on harnessing the power of Meta’s Llama AI model to summarize and question PDF files. In this tutorial, we will walk you through the steps needed to build a Streamlit application that can upload a PDF, extract its text, summarize it, and answer questions based on the content. By the end of this blog, you will have a fully functional app and a solid understanding of the underlying concepts.
Getting Started
Before diving into the code, ensure you have all the necessary libraries installed on your machine. You will need to install the following packages:
streamlit– for building the web applicationrequests– for making API callsPyPDF2– for extracting text from PDF files
To install these libraries, run the following command:
pip install streamlit requests PyPDF2
Extracting Text from PDFs
The first step in our application is to extract text from the uploaded PDF file. We will create a function called extract_text_from_pdf that takes the path of the PDF file as input, reads its content, and returns the extracted text.
def extract_text_from_pdf(pdf_path):
from PyPDF2 import PdfReader
text = ""
with open(pdf_path, "rb") as file:
reader = PdfReader(file)
for page in reader.pages:
text += page.extract_text() + "\n"
return text
In this code snippet, we use the PdfReader class from the PyPDF2 library to read the PDF file page by page and accumulate the text into a single string.
Testing Groq’s API
Next, we need to test the Groq API key to ensure it works correctly. For this tutorial, we will be using the Groq client to call our Llama model. If you haven’t already created an account with Groq, you can do so for free and generate your API key.
import requests
API_KEY = "your_api_key"
headers = {"Authorization": f"Bearer {API_KEY}"}
response = requests.get("https://api.groq.com/models", headers=headers)
print(response.json())
Replace your_api_key with your actual API key. If everything is set up correctly, you should receive a response from the API.
Creating the Summarization Function
Now that we have our text extracted and our API tested, let’s create the summarize_text function. This function will take the extracted text as input and return a summary using the Llama model.
def summarize_text(text):
url = "https://api.groq.com/v1/summarize"
payload = {"text": text}
response = requests.post(url, headers=headers, json=payload)
return response.json()["summary"]
In this function, we send a POST request to the Groq API with the text we want to summarize. The API will return a summary that we can display in our app.
Questioning the Text
Next, we want to implement a function to allow users to ask questions about the summarized text. This function will take the context (the text) and the question as inputs and return the model’s response.
def ask_question(context, question):
url = "https://api.groq.com/v1/question"
payload = {"context": context, "question": question}
response = requests.post(url, headers=headers, json=payload)
return response.json()["answer"]
This function works similarly to the summarization function, but it sends both the context and the question to the API to get a relevant answer.
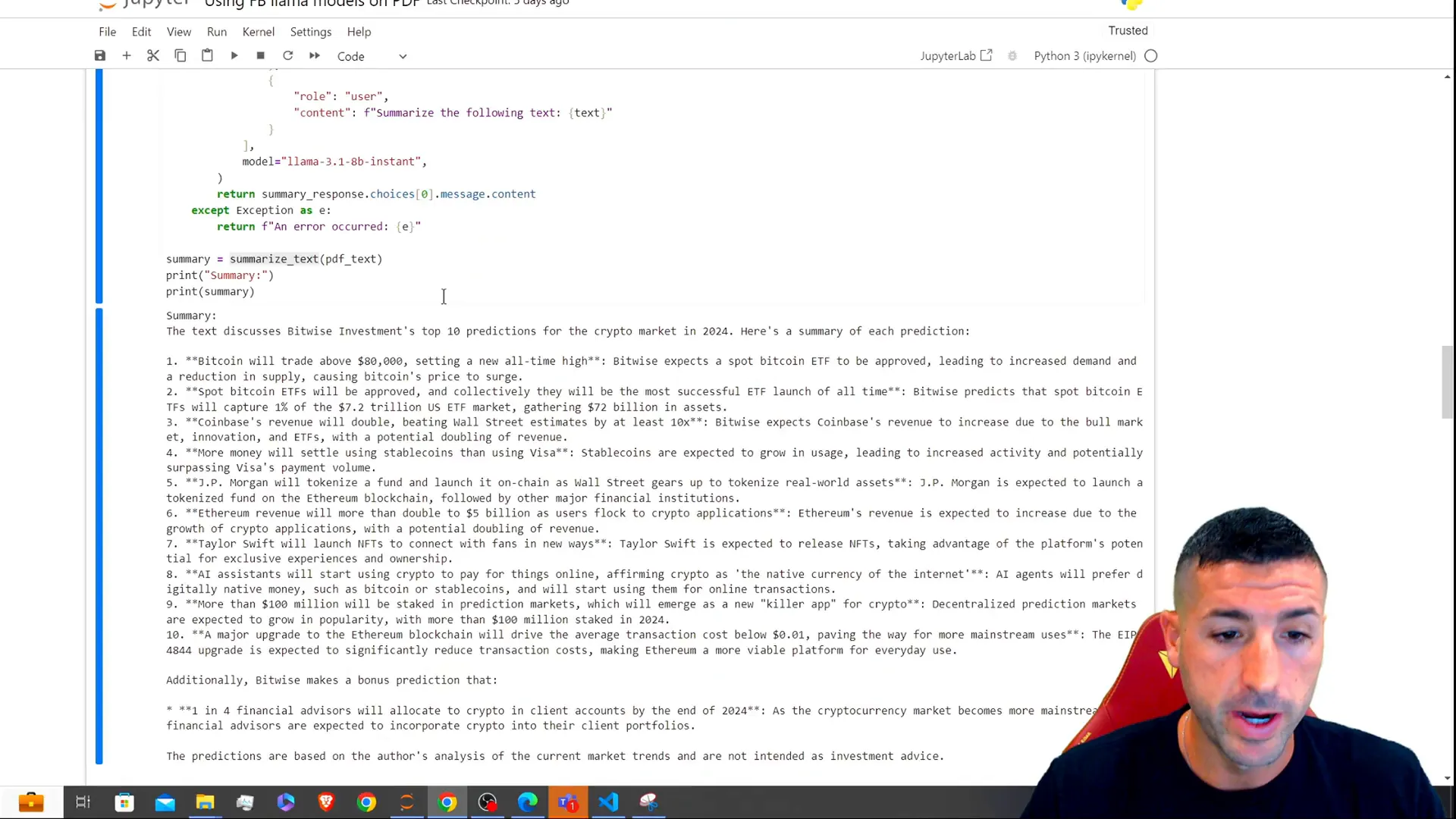
Building the Streamlit App
With our functions in place, we can now build the Streamlit app. We will create an interface that allows users to upload a PDF, see the extracted text, get a summary, and ask questions.
import streamlit as st
st.title("PDF Summarizer and Question Answering App")
pdf_file = st.file_uploader("Upload a PDF file", type="pdf")
if pdf_file is not None:
pdf_text = extract_text_from_pdf(pdf_file)
st.subheader("Extracted Text")
st.write(pdf_text[:1000]) # Display first 1000 characters
if st.button("Summarize Text"):
summary = summarize_text(pdf_text)
st.subheader("Summary")
st.write(summary)
question = st.text_input("Ask a question about the PDF:")
if st.button("Get Answer"):
answer = ask_question(pdf_text, question)
st.subheader("Answer")
st.write(answer)
This code sets up the main components of the Streamlit app, including file upload, text display, summarization, and question answering functionalities.
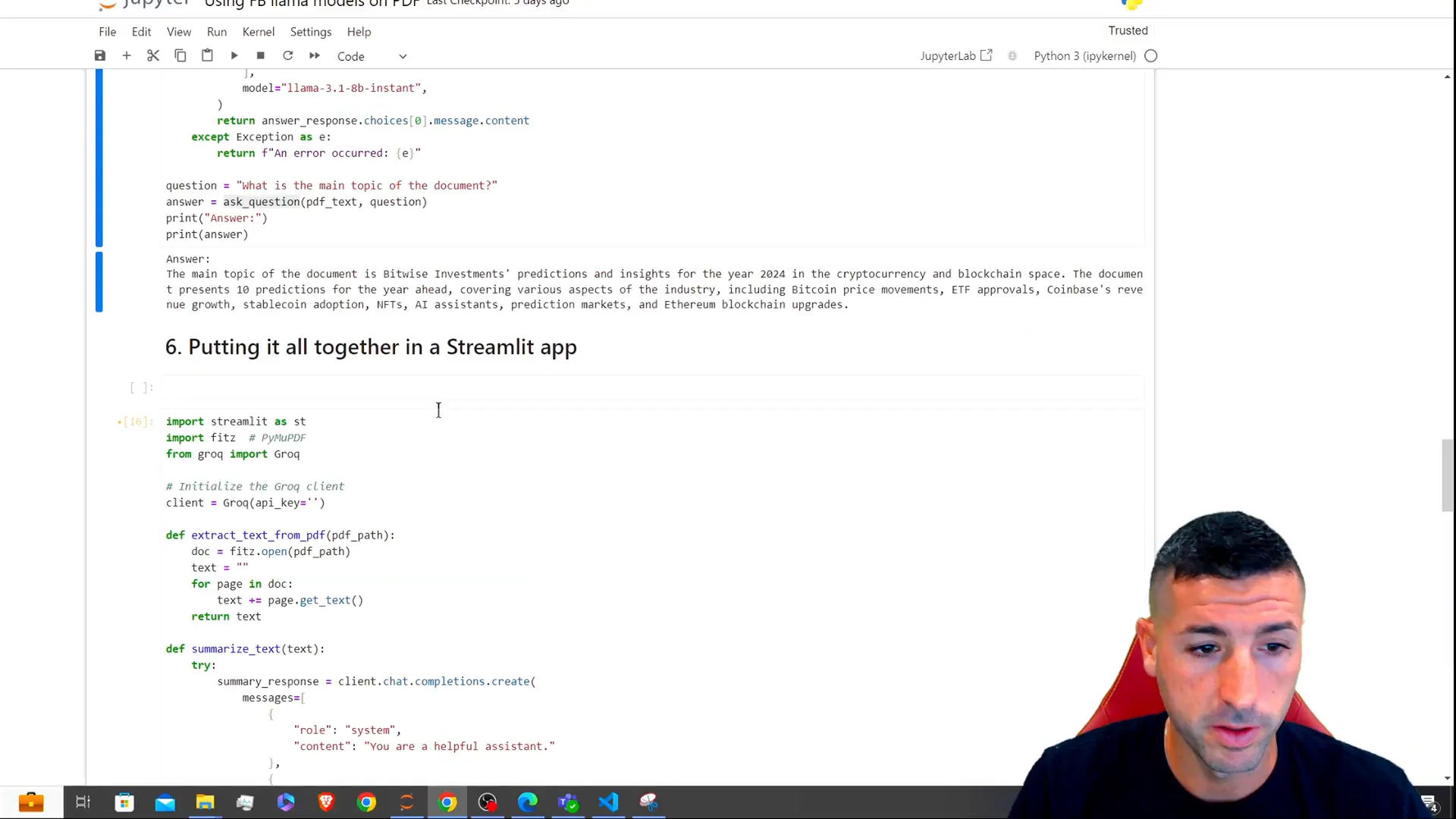
Deploying the App
To deploy the app, save your code in a file named app.py and run the following command in your terminal:
streamlit run app.pyThis command will launch your Streamlit app in your default web browser, where you can test its functionalities.
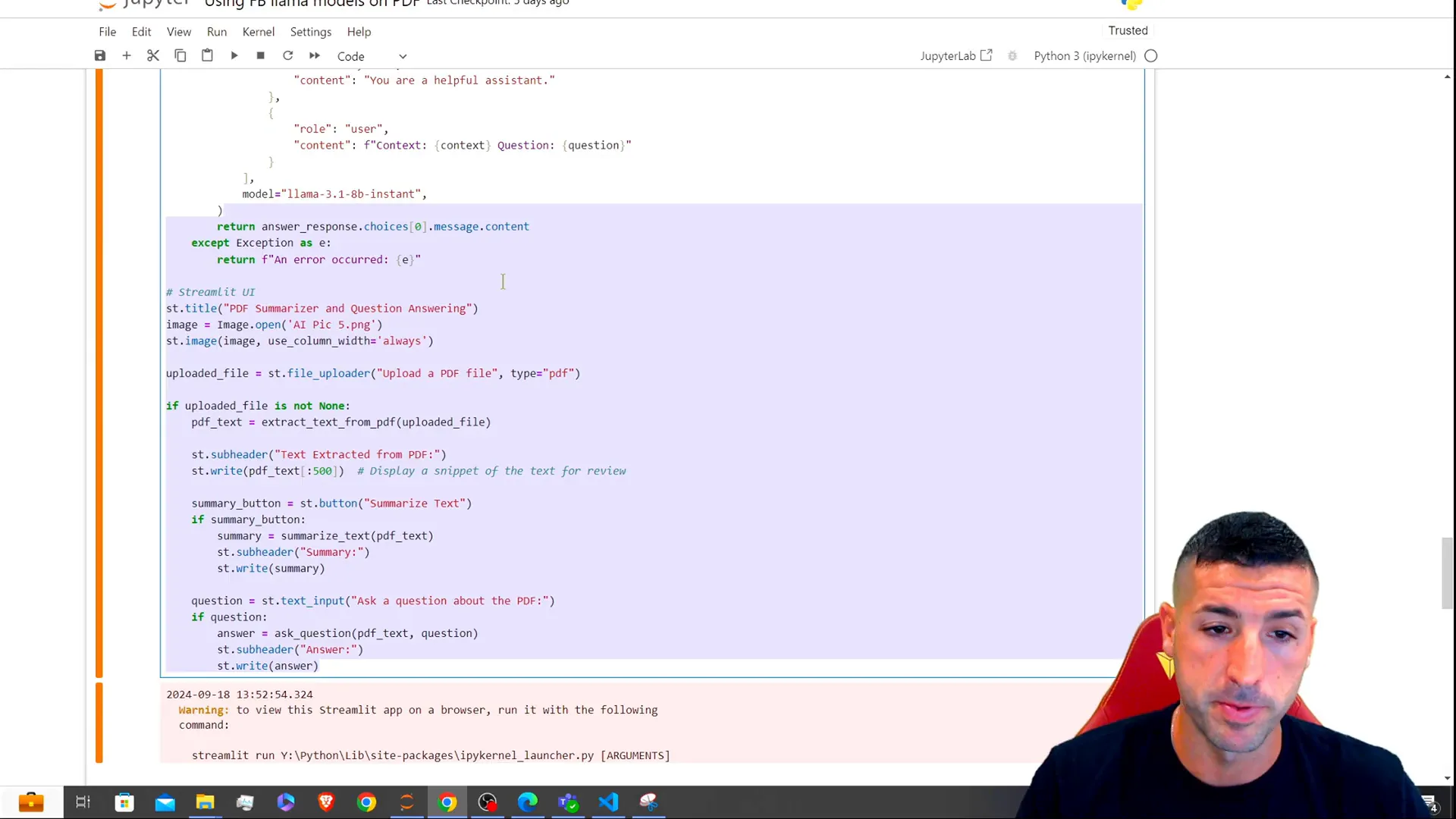
Performance Evaluation
Once your app is running, you can evaluate its performance by uploading different PDF files and testing the summarization and questioning features. Make sure to monitor the API responses for any rate limits or errors.
Conclusion
In this tutorial, we explored how to use Meta’s Llama AI model to summarize and question PDF files with a Streamlit application. By following the steps outlined, you can create an interactive tool that leverages the power of AI to enhance your document processing capabilities. If you found this guide helpful, consider sharing it with others who might benefit from it!
For the complete code and further resources, check out the GitHub repository.
Feel free to connect with me on X for more updates!