
{kind=link}
In the field of science and artificial intelligence utilizing language models (LLMs) has gained traction. This article will walk you through the steps of creating a Streamlit application that utilizes OpenAIs API to summarize PDF files and respond to inquiries based on their content. By the conclusion of this tutorial you’ll possess a working chatbot application capable of managing PDF documents.
Getting Started
Before we jump into the code let’s talk about the libraries and tools required to build your PDF summarization and question answering application.
Required Libraries
To get started you’ll need to set up a few libraries.
- PDFPlumber: This library helps in extracting text from PDF files.
- OpenAI: This is the API that allows you to interact with the OpenAI models, such as ChatGPT.
- Streamlit: This library helps you create web applications using Python.
- Pillow: This library is used for image processing if you want to include images in your app.
You can install these libraries by using the command.
pip install pdfplumber openai streamlit pillow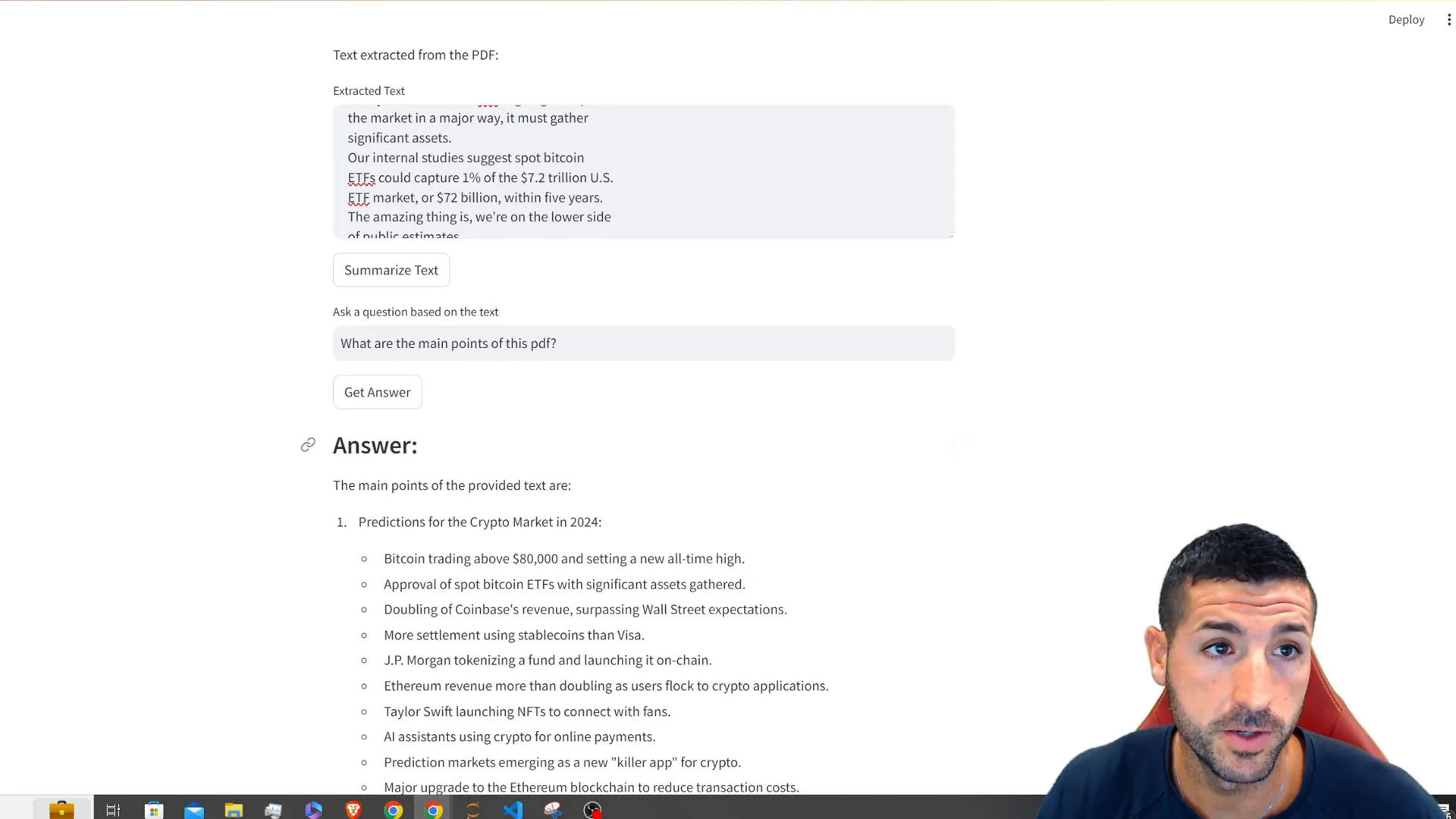
Setting Up the OpenAI API Key
Now it’s time to configure your OpenAI API key. This key is crucial for sending requests to the OpenAI API. If you haven’t registered an account with OpenAI you can sign up and obtain your API key through their platform.
After obtaining your API key you can incorporate it into your application code as demonstrated below:
import openai
openai.api_key = 'YOUR_API_KEY'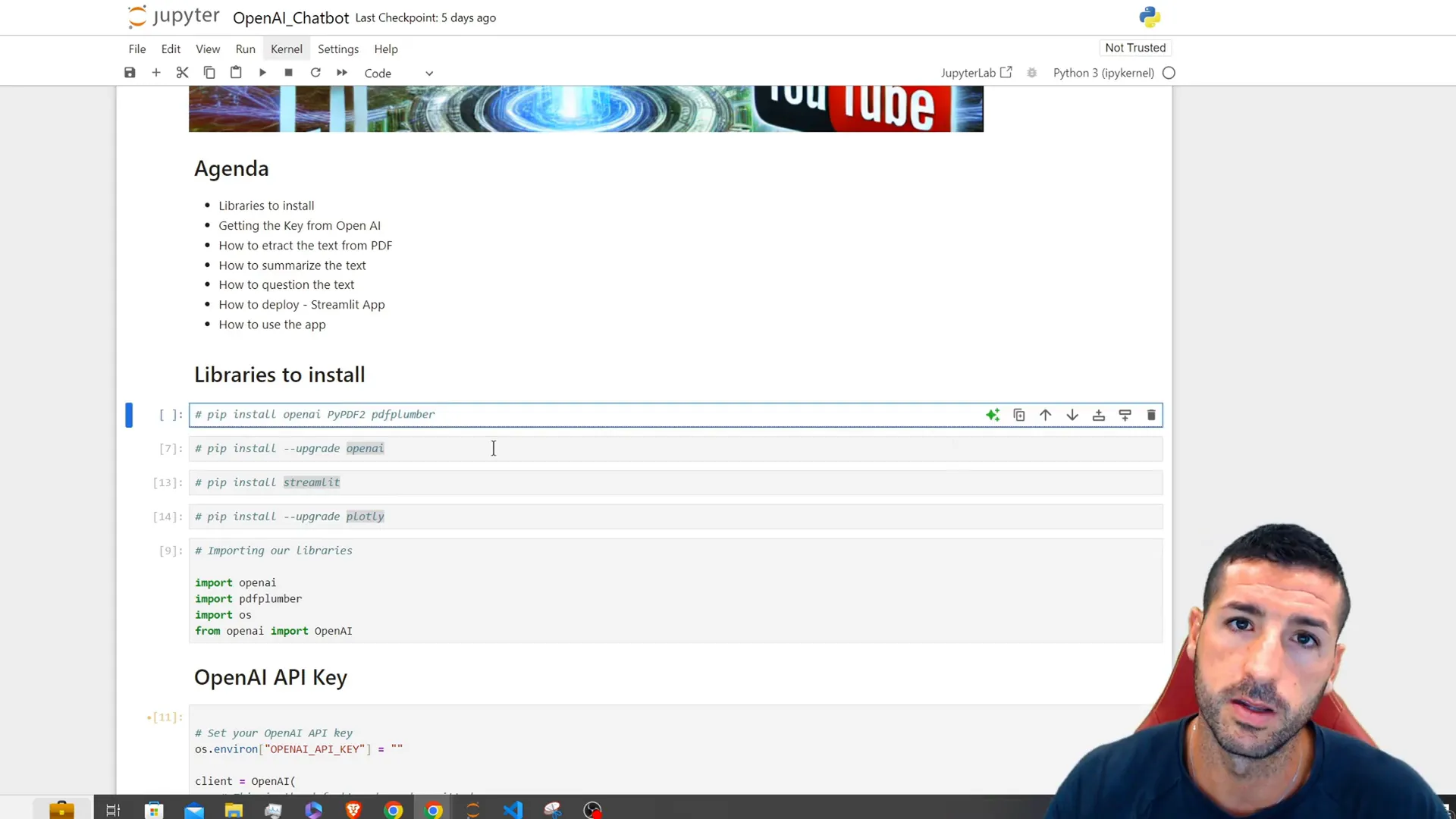
Extracting Text from PDF Files
Now, let’s develop a function that can pull out text from a PDF document. We’ll utilize the PDFPlumber library for this task. The function will go through the PDF file one page at a time and provide the extracted text as output.
import pdfplumber
def extract_text_from_pdf(pdf_path):
text = ""
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
text += page.extract_text() + "\n"
return text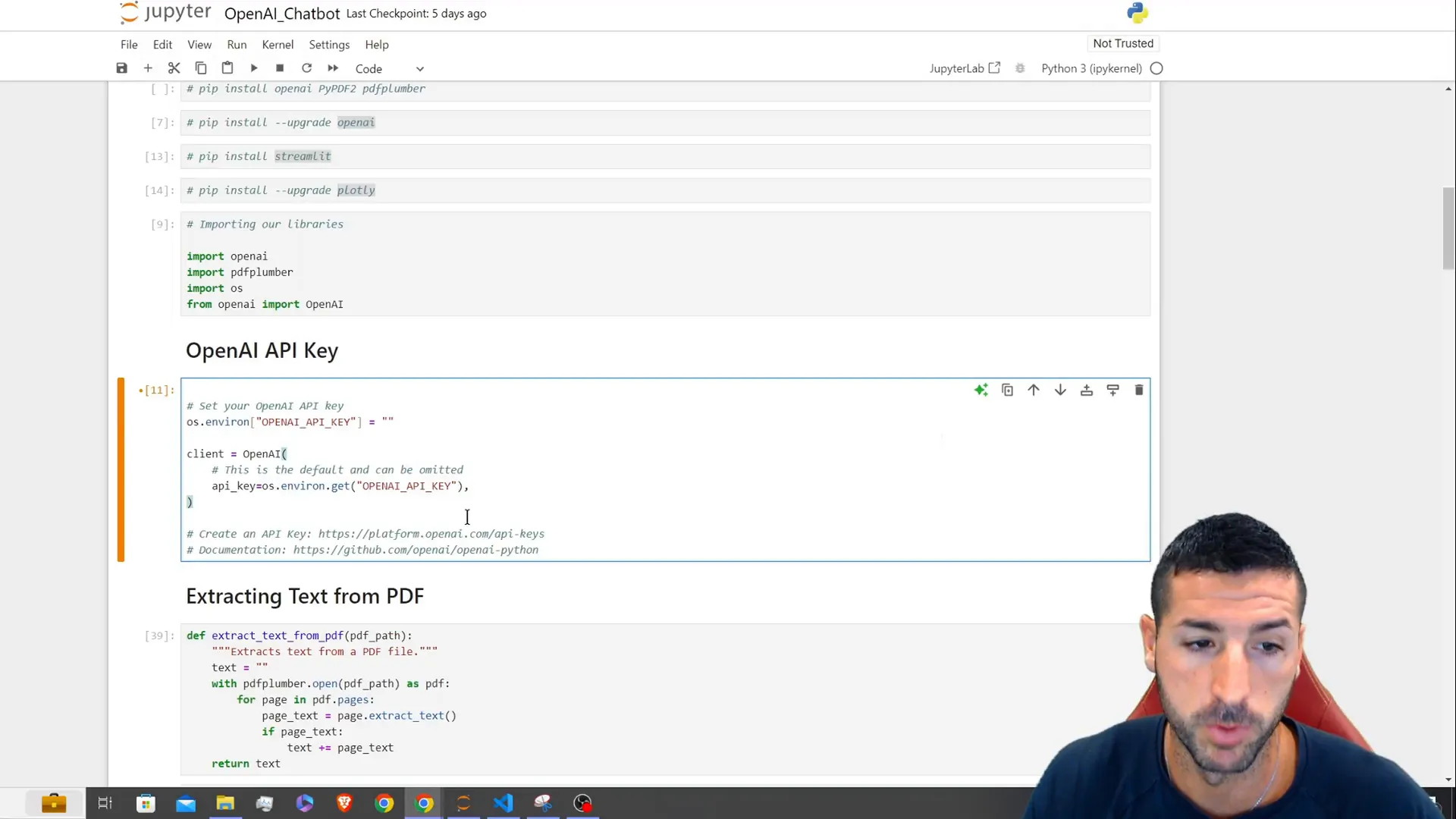
Summarizing the Extracted Text
Next up well be developing a function that leverages the OpenAI API to condense the extracted content. This function will transmit the text to the OpenAI model and provide a summarized version in return.
def summarize_text(text):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant that summarizes text."},
{"role": "user", "content": f"Summarize the following text: {text}"}
],
max_tokens=300,
temperature=0.5
)
return response.choices[0].message['content']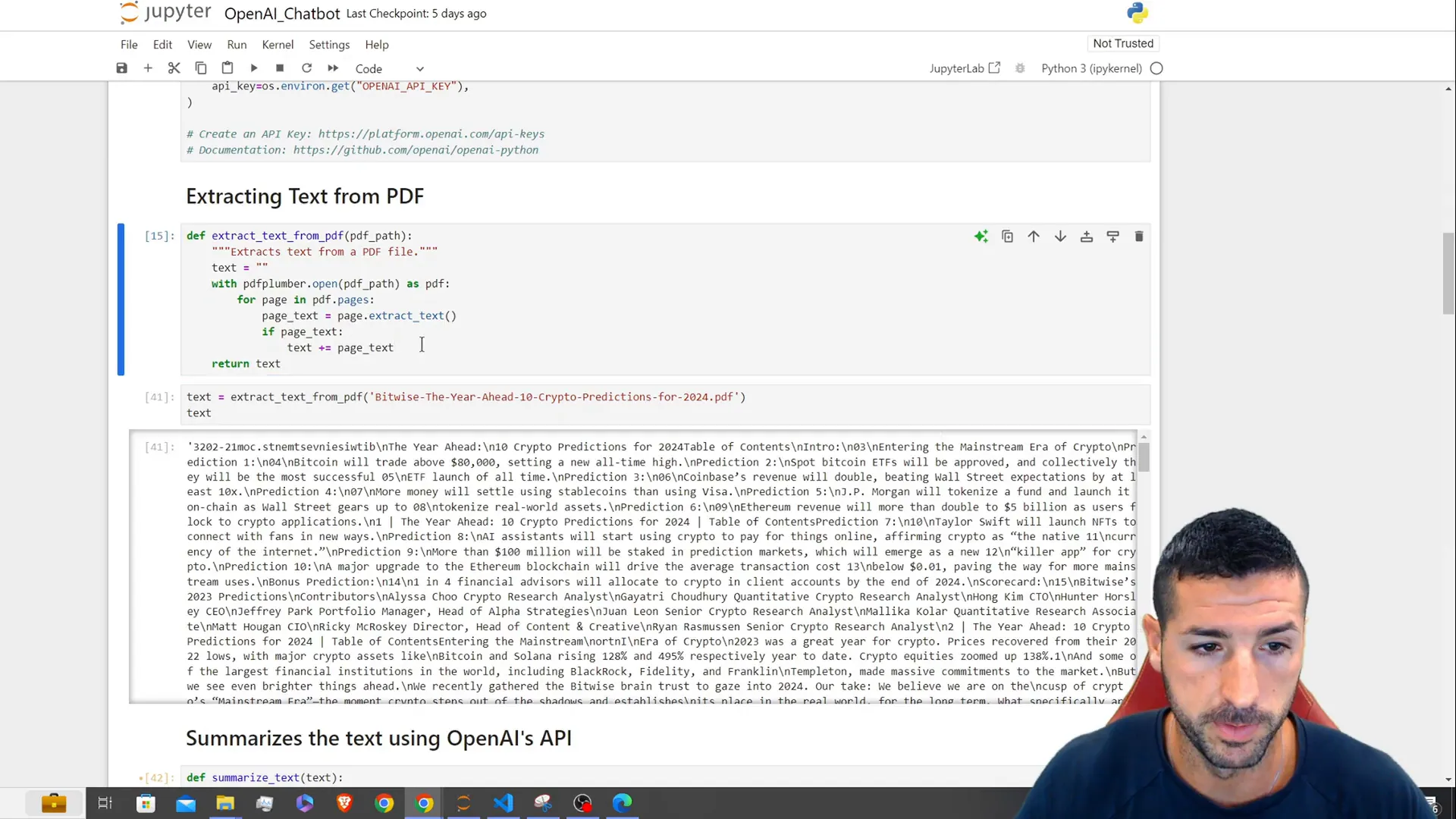
Asking Questions about the PDF
To enhance the interactivity of our application we plan to implement a feature that enables users to inquire about the information contained in the PDF. This feature will utilize the text and the users query to generate a response using the OpenAI model.
def ask_question(text, question):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"Based on the following text, answer this question: {question} Text: {text}"}
],
max_tokens=300,
temperature=0.5
)
return response.choices[0].message['content']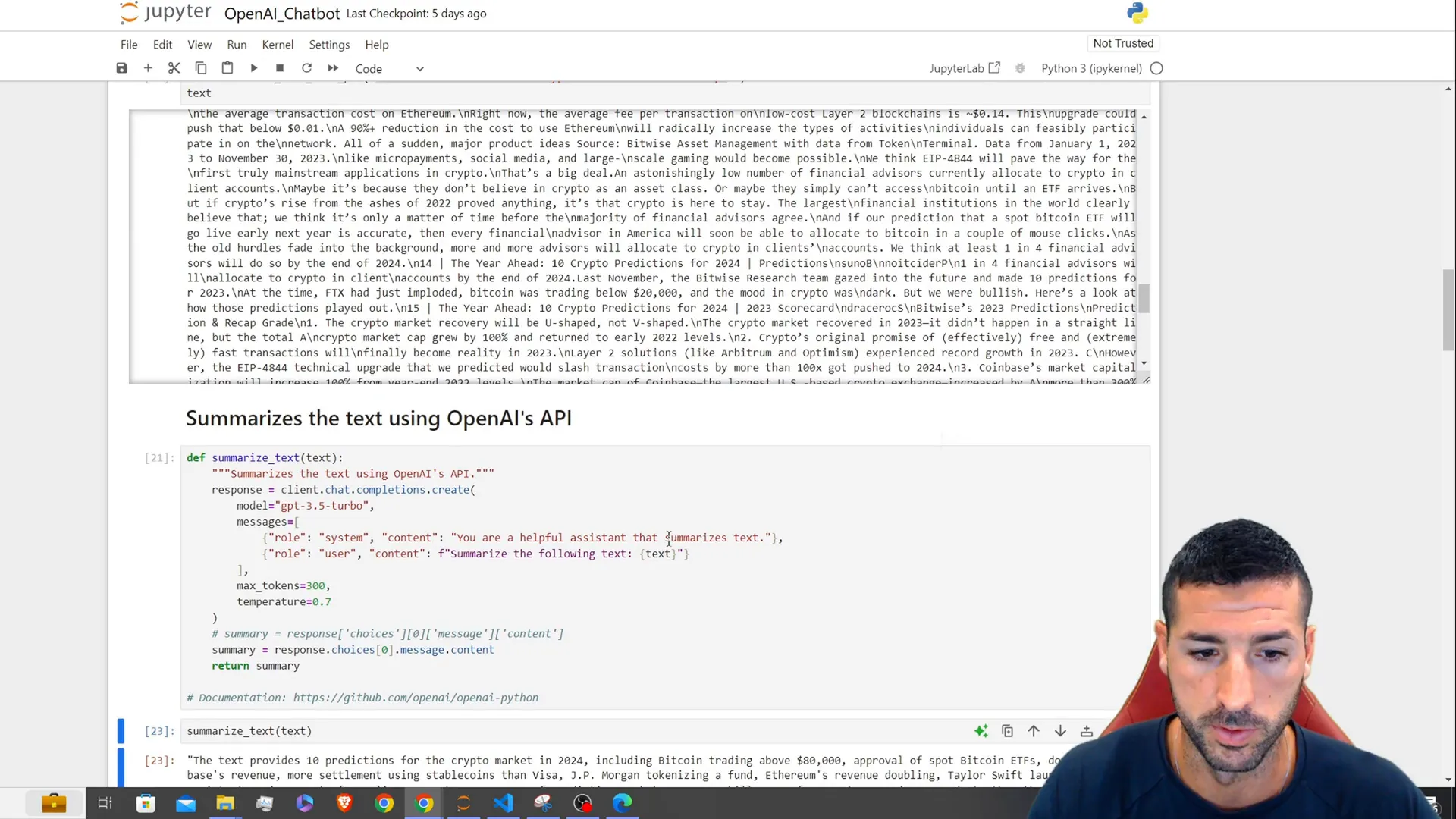
Creating the Streamlit Application
With our functions prepared its time to build the Streamlit application. Well start by setting the title then implement a file uploader for the PDF format. Additionally well include buttons for generating summaries and posing questions.
import streamlit as st
st.title("PDF Summarization and Question Answering Chatbot")
uploaded_file = st.file_uploader("Choose a PDF file", type="pdf")
if uploaded_file is not None:
text = extract_text_from_pdf(uploaded_file)
st.subheader("Text Extracted from PDF")
st.text_area("Extracted Text", text, height=300)
if st.button("Summarize Text"):
summary = summarize_text(text)
st.subheader("Summary")
st.write(summary)
question = st.text_input("Ask a question about the text")
if st.button("Get Answer"):
answer = ask_question(text, question)
st.subheader("Answer")
st.write(answer)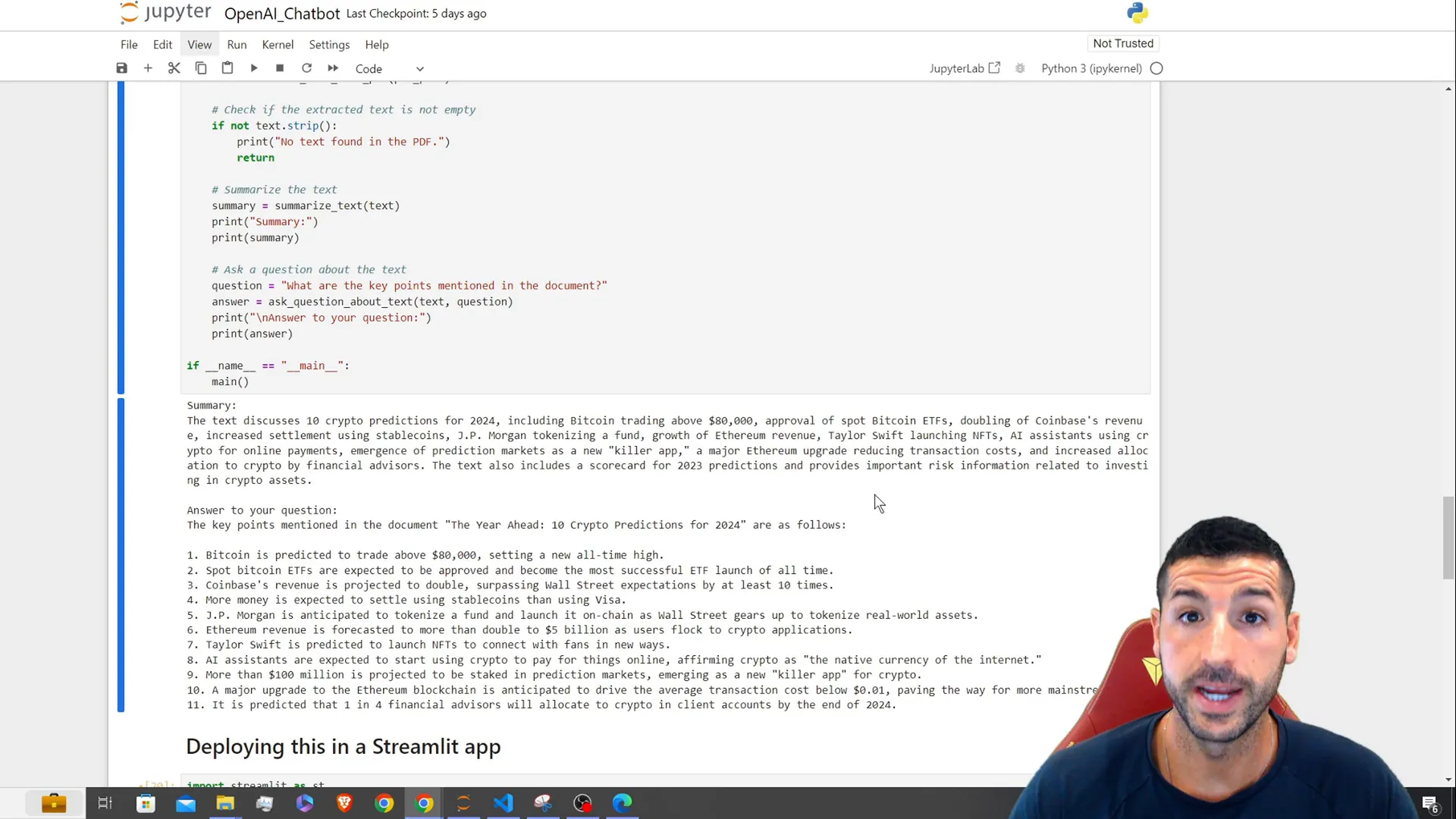
Deploying the Streamlit App
Once you’ve built the application you can execute it by using the following command.
streamlit run your_app.pyBy running this command you will initiate a server and access your application through the web browser.
Testing the App
Once your application is up and running you can test it out by uploading a PDF document summarizing what it says and asking questions based on it. Be sure to experiment with PDF files to gauge its performance!
Conclusion
Well done! You’ve created a chatbot app that summarizes PDF files and responds to queries about their content using Python, OpenAIs API and Streamlit. You’re encouraged to experiment with and customize the code to improve your app even more.
If you have any inquiries or suggestions feel free to drop a comment below. Enjoy your coding journey!